Self-attention mechanism and Transformers
This blog talks about the historical developement of self-attention mechanism and the implementation of transformer decoder.
 screenshot of attention mechanism
screenshot of attention mechanism
1. 明确输入输出
将输入转化为vector
- 文本翻译 – 将词汇转化成same length vector(word2vector,one-hot coding)
- 信号处理 – 生成一段时长的window 将其中内容转化为一个frame vector 然后跳一个gap向前
- 图(graph) – 每一个node的信息汇总成vector vertices单独拎出来和后面attention matrix结合
- 图像 – 每一个pixel有三通道的向量 DETR
明确输出类型
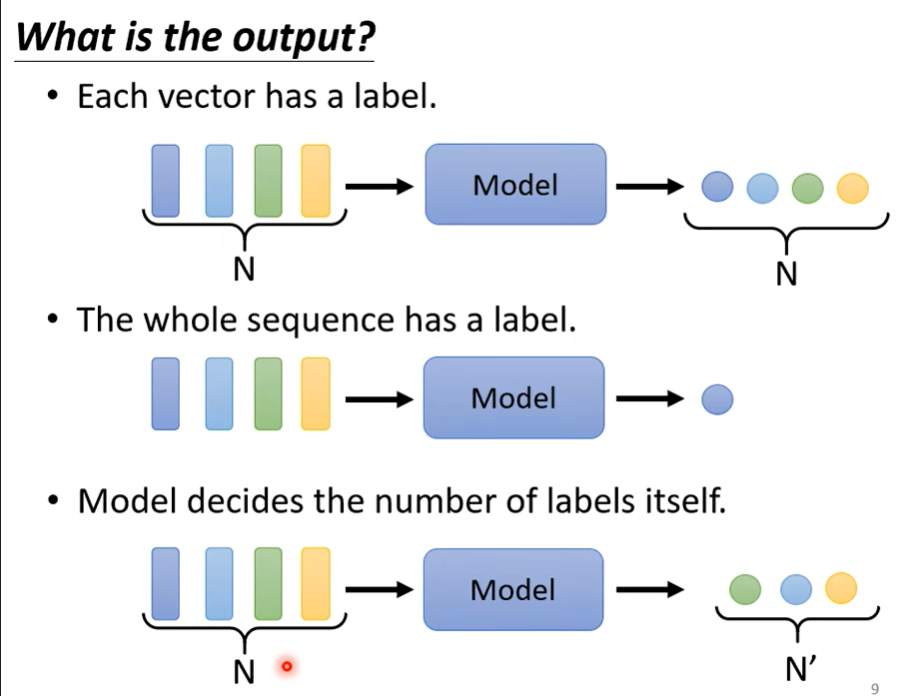
例子:文本处理词性标注(POS tagging) / 一句话的感情分析(sentiment analysis) / model自己选择输出大小
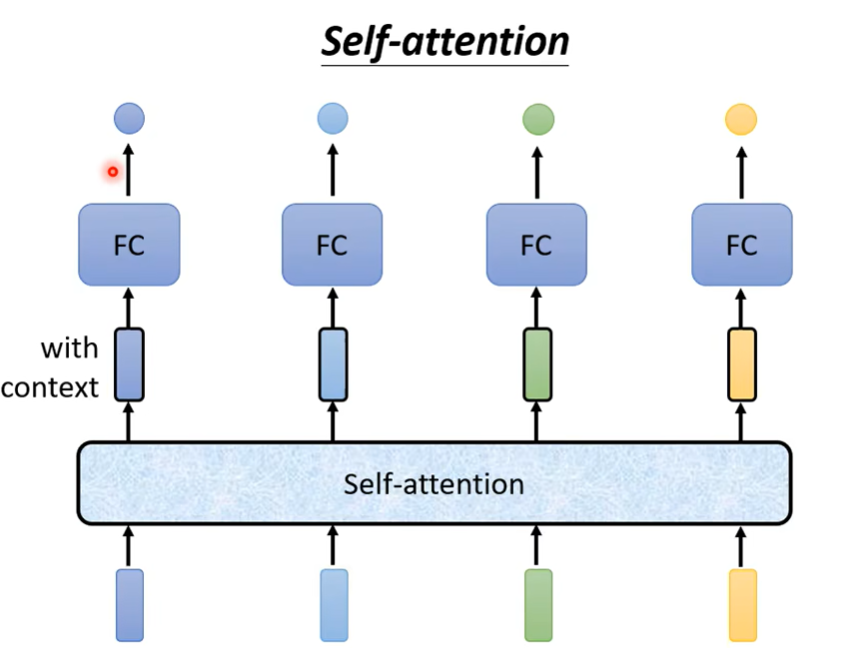
第一类问题(Sequence Labeling)
1. 面对的问题
(1)给一个sequence 如何生成corresponding sequence / labels
如果使用单一的fully-connected layers,那么给定的sequence长度随着时间变化,则无法做到泛化
因此我们需要一个flexible的方法 不用限定sequence的长度
(2)如何体现sequence的上下文信息对当前vector的output的影响
双向RNN能够体现上下文 用一个window将需要考虑的相邻向量容纳进去 但是无法平行计算(parallel – speedup)
2. Self-attention
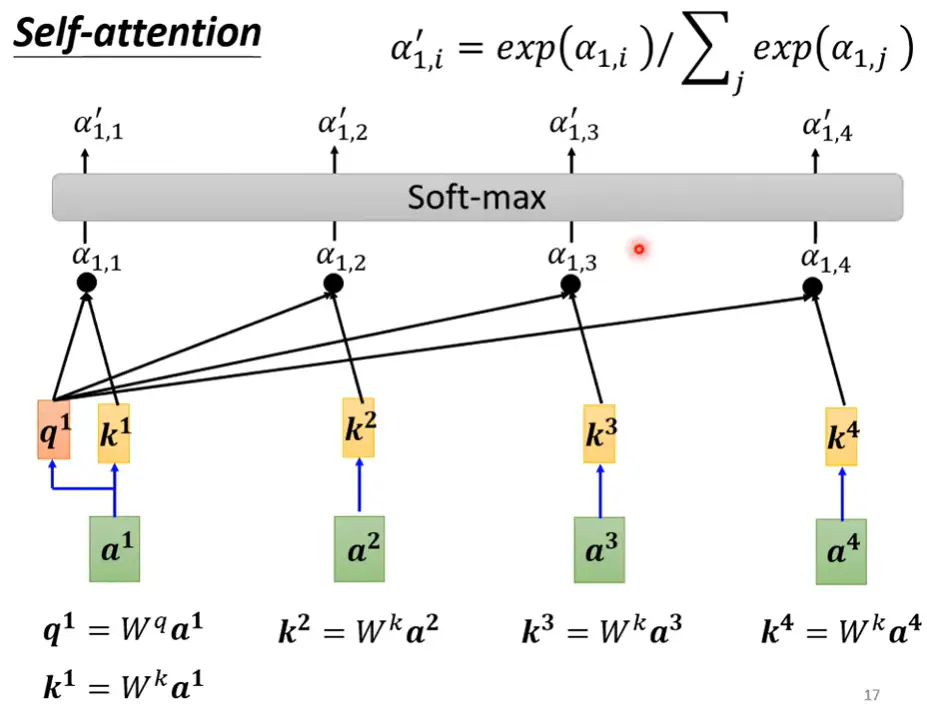
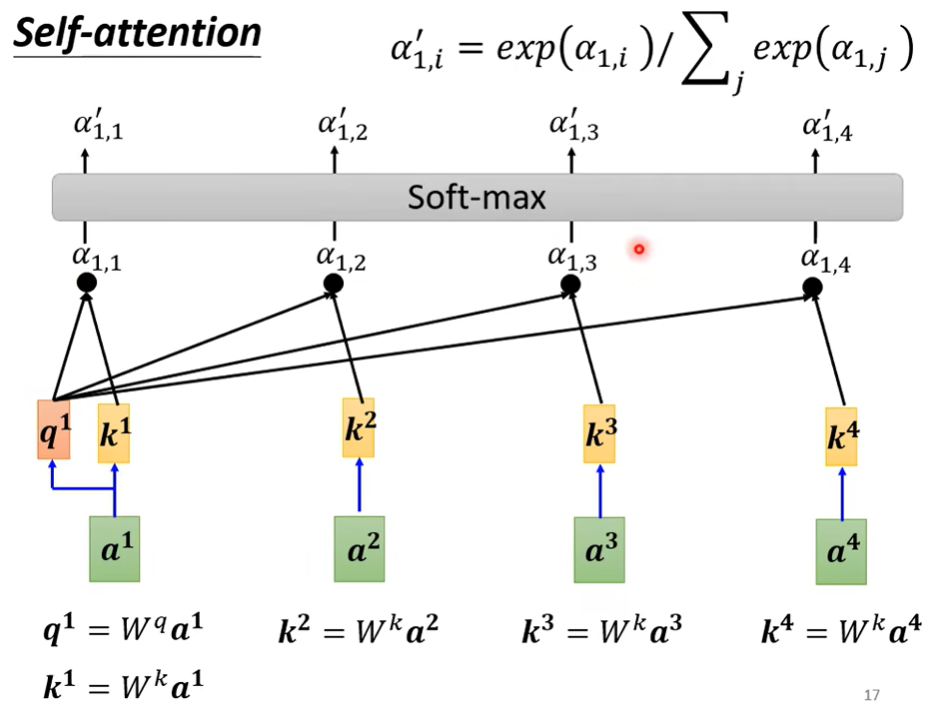
(1) 解决的方法
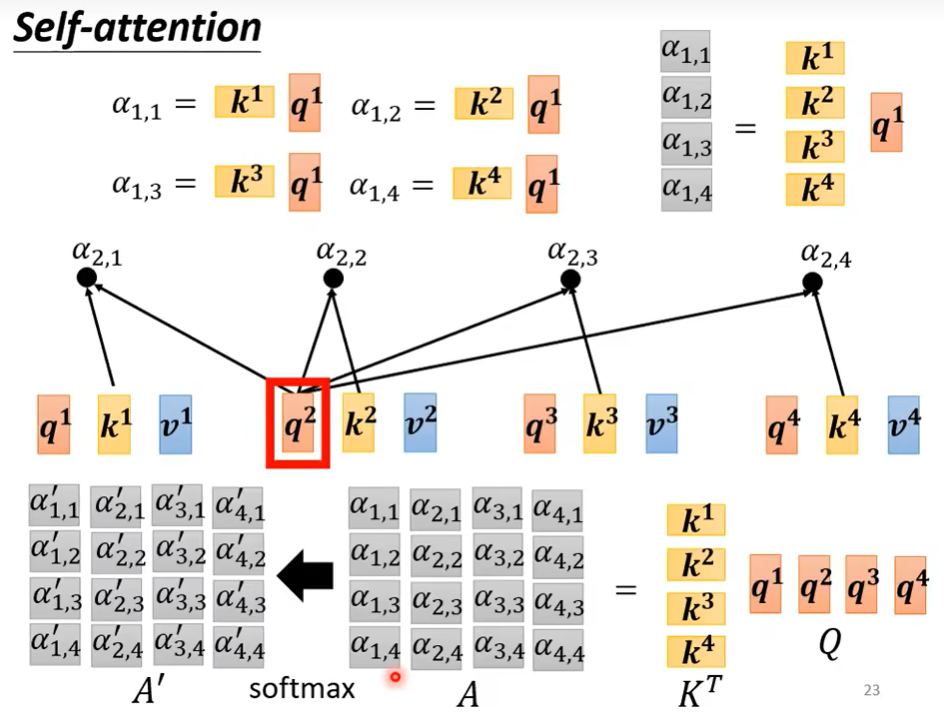
1. Attention Score $\alpha$ – 体现上下文信息
每个input向量之间会计算一个attention score 用来表示相似性 (计算方法有很多例如dot-product / addictive)
2. 引入positional encoding
针对每一个attention layer 无论sequence的顺序如何,他都不影响结果输出,这表示no position information in self-attention – 天涯若比邻 每个向量之间的距离都是“一样的”
引入unique positional vector $e^i$
(2) 流程
1. 生成每一个向量的Query Key Value
每一层attention layer共享一个Query Key Value matrix $$W^q \ W_k \ W_v$$
引入三个变量是为了引入更多可学习的参数,但是共享参数是为了减少训练量
2. Q K 组合生成 $\alpha$ Soft-max 后生成 $\alpha^{\prime}$
下图为第一个向量与sequence中所有向量的attention score计算示意图
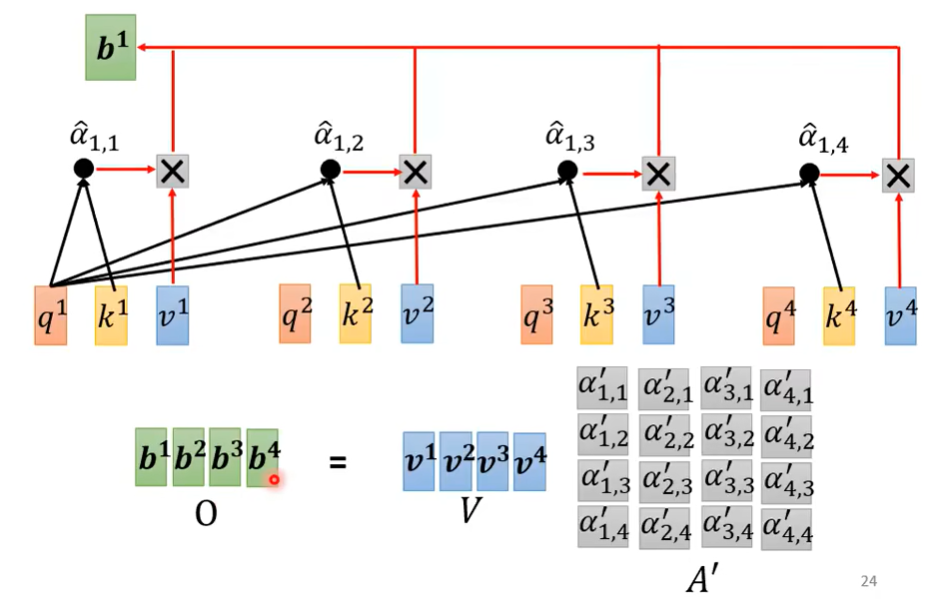
3. Extract information based on attention scores
$$ \boldsymbol{b}^{\mathbf{1}}=\sum_{i} \alpha_{1, i}^{\prime} \boldsymbol{v}^{i} $$
(3) Matrix representation
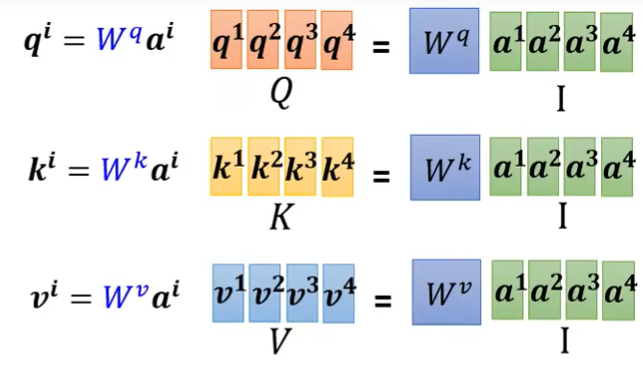
 $$
\begin{aligned}
Q &= w^q · I \\
K &= w^k · I \\
V &= w^v · I \\
A^{\prime} = softmax(A) &= softmax(K^T Q) \\
O &= V A^{\prime}
\end{aligned}
$$
$$
\begin{aligned}
Q &= w^q · I \\
K &= w^k · I \\
V &= w^v · I \\
A^{\prime} = softmax(A) &= softmax(K^T Q) \\
O &= V A^{\prime}
\end{aligned}
$$
3. Multi-head Self-attention
different types of relevance
4. Self-attention VS CNN
CNN: self-attention that can only attends in a receptive field
self-attention: CNN with learnable receptive field (complex version of CNN)
On the Relationship between Self-Attention and Convolutional Layers
小样本数据集上CNN模型小更高效 大数据集样本上self-attention往往能找到更多的connection
5. Self-attention VS RNN
RNN递进关系会导致远距离很难考虑 并且 不是平行架构无法加速
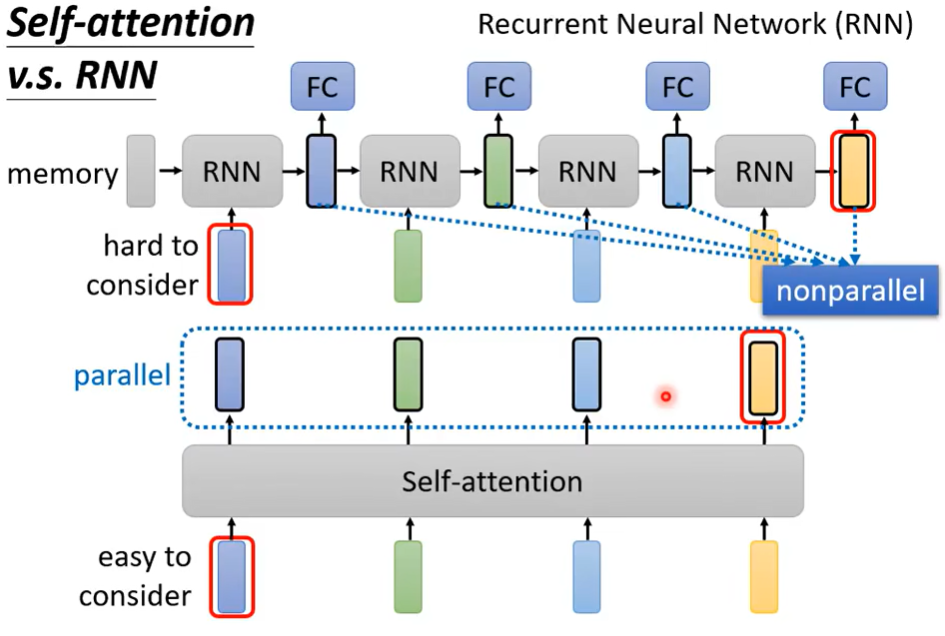
Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention
6. 综述文章
Efficient Transformers: A Survey
Long Range Arena: A Benchmark for Efficient Transformers
Transformers
Sequence-to-sequence(seq2seq)
Input a sequence, output a sequence.
The output length is determined by model.
seq2seq for object detection – End-to-End Object Detection with Transformers
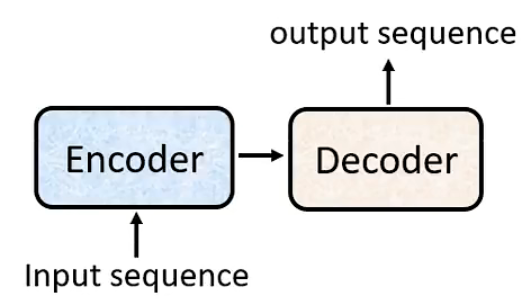
Transformer’s Encoder – Self-attention
encoder的核心问题 是将一个sequence的向量如何转化为同样长度的向量
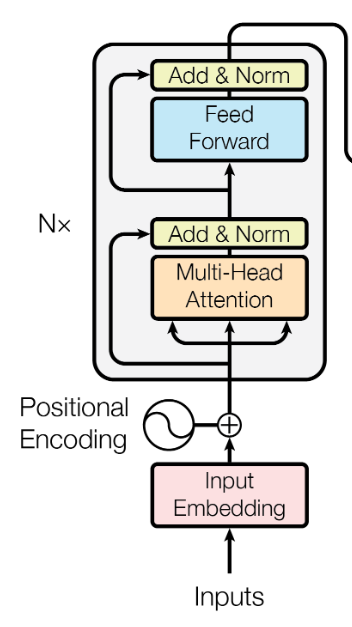
每一个block的处理顺序
-
self-attention
-
residual connection (防止梯度消失)
为什么residual block能够防止梯度消失?
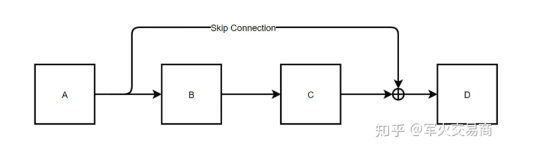
根据后向传播的链式法则,
$$ \frac{\partial L}{\partial X_{\text{Aout}}} = \frac{\partial L}{\partial X_{\text{Din}}} \cdot \frac{\partial X_{\text{Din}}}{\partial X_{\text{Aout}}} $$ $$ \because X_{\text{Din}} = X_{\text{Aout}} + C(B(X_{\text{Aout}})) $$ $$ \frac{\partial L}{\partial X_{\text{Aout}}} = \frac{\partial L}{\partial X_{\text{Din}}} \cdot \left[ 1 + \frac{\partial X_{\text{Din}}}{\partial X_{\text{Cout}}} \frac{\partial X_{\text{Cout}}}{\partial X_{\text{Bout}}} \frac{\partial X_{\text{Bout}}}{\partial X_{\text{Aout}}}\right] $$ $$ = \frac{\partial L}{\partial X_{\text{Din}}} + \frac{\partial L}{\partial X_{\text{Din}}}\frac{\partial X_{\text{Din}}}{\partial X_{\text{Cout}}} \frac{\partial X_{\text{Cout}}}{\partial X_{\text{Bout}}} \frac{\partial X_{\text{Bout}}}{\partial X_{\text{Aout}}} $$ $$ = \frac{\partial L}{\partial X_{\text{Din}}} + \text {original loss gradient} $$
通常微分后都小于1 故原始梯度容易越算越小 到前端就容易消失无法改变
- norm (layer normalization)同一个向量的不同dimension计算mean和deviation
$$ \begin{bmatrix} x_1 & x_2 & \cdots & x_K \end{bmatrix}^{T} \rightarrow \begin{bmatrix} x_1^{\prime} & x_2^{\prime} & \cdots & x_K^{\prime} \end{bmatrix}^{T} $$
batch normalization是对同一个dimension不同的feature的mean和variance(不同向量之间的$x_i$的$\mu$)
[以下是encoder的详细说明](#Transformer’s Encoder – Self-attention)
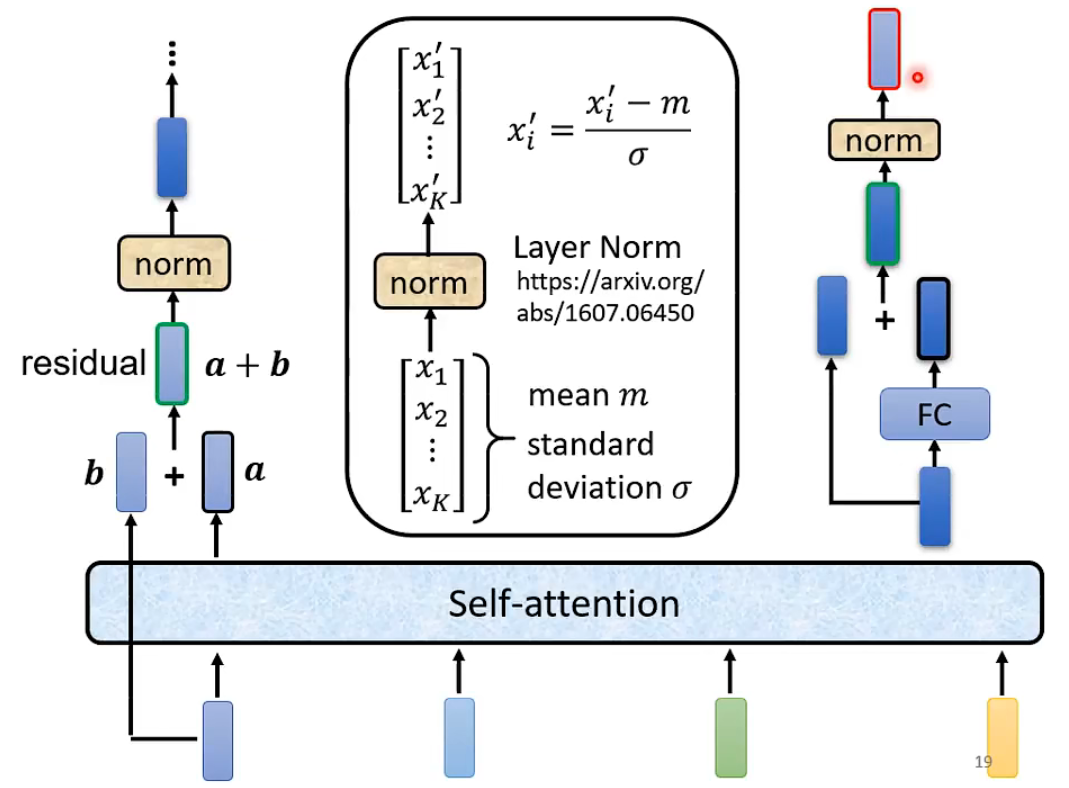
Encoder架构的变形
- [2002.04745] On Layer Normalization in the Transformer Architecture (arxiv.org)
- [2003.07845] PowerNorm: Rethinking Batch Normalization in Transformers (arxiv.org)
Transformer’s decoder
输出方式 – Autoregressive 和 non-autoregressive
- 将decoder的sequence vectors输入decoder
- autoregressive – 决定了decoder的输出方式(AT)
- 首先在decoder里输入vectors
- 输入begin of sentence(通常为one-hot coding vector)
- 第一个输出为一个长度为想要输出的范围的size长度的vector 再经过softmax得到distribution 取最大值
- 再将第一个输出当成新的输入(改成one-hot coding) 此时decoder输入有bos和之前的输出
- 再得到新的输出
- 以此类推
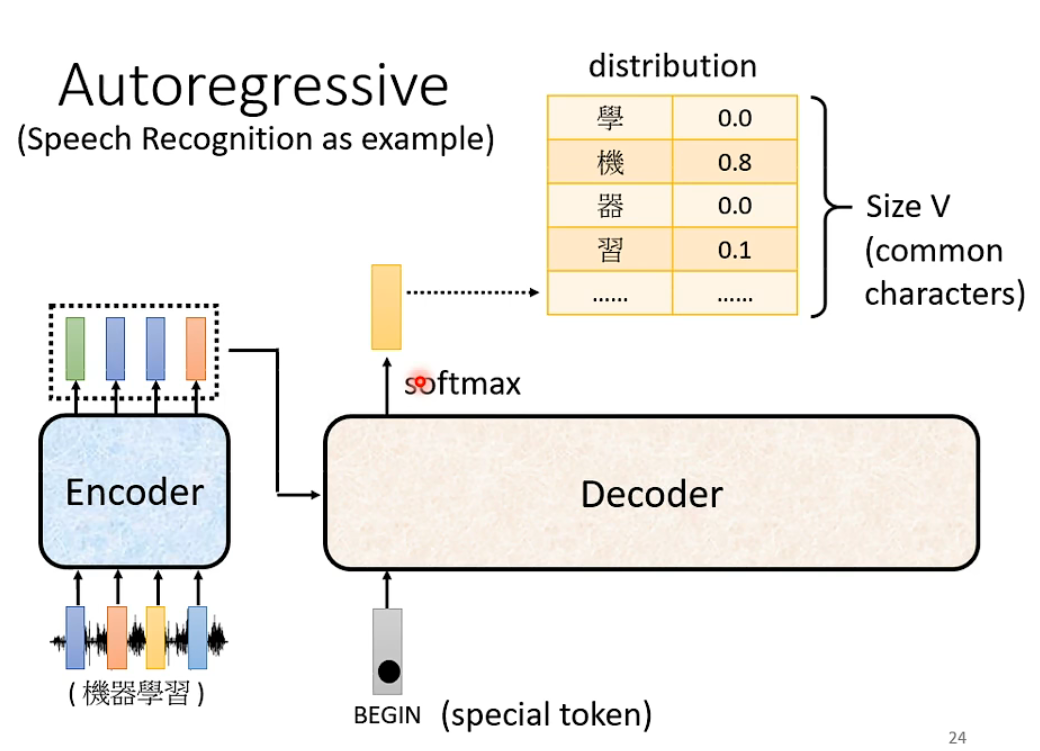
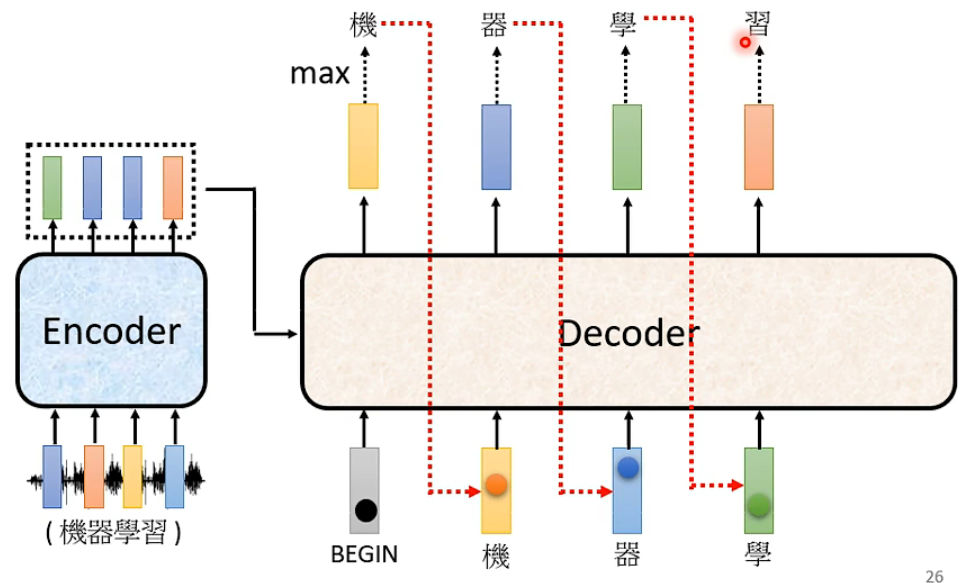
Decoder 本身架构
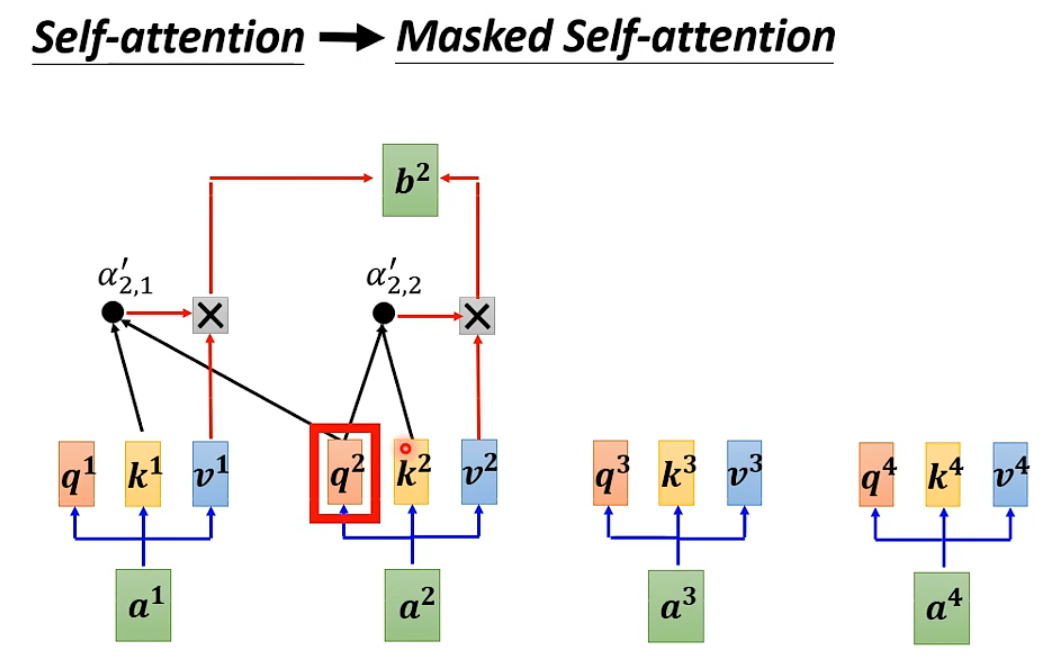
- 抛去中间的block 可以看到就是与decoder 相似的主体结构 唯一不同的是masked self-attention,很好理解不能剧透后面的部分。(类似于RNN)
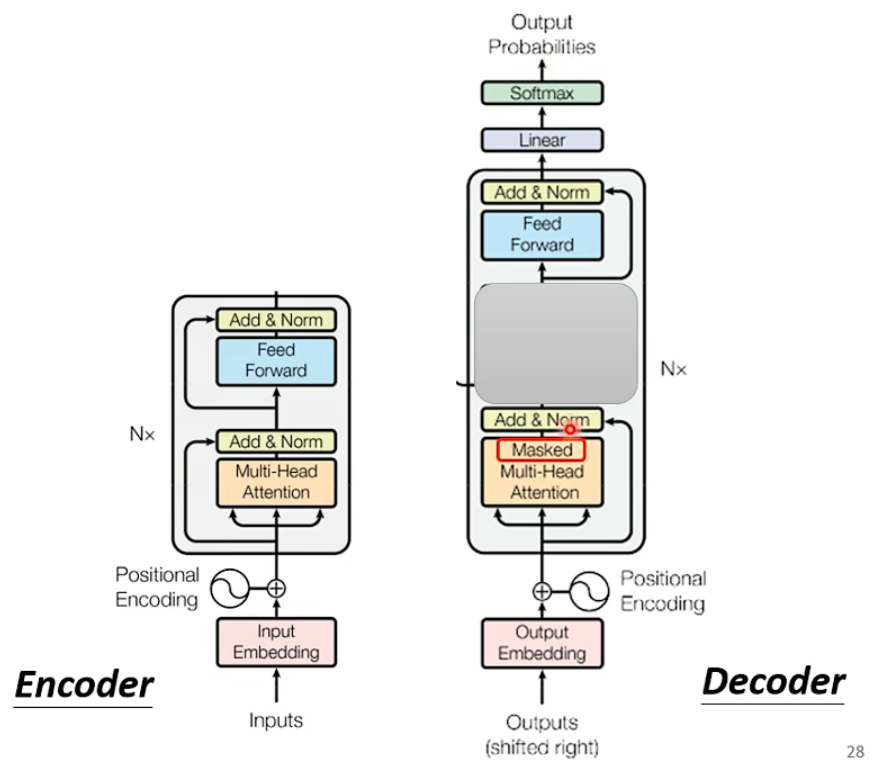
eg.
Encoder和decoder如何交互?
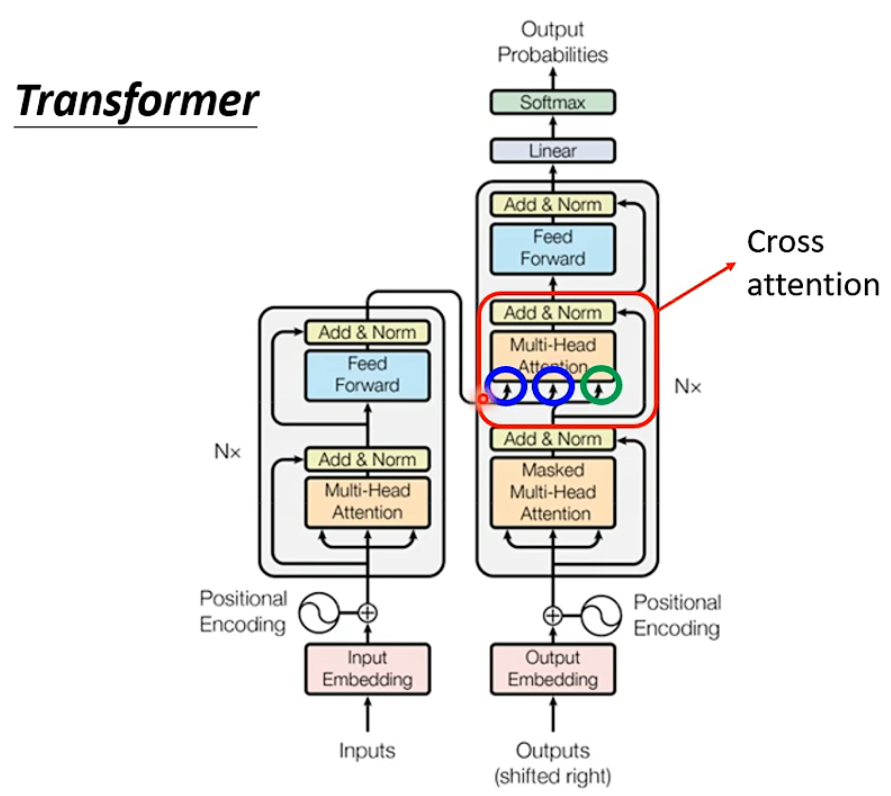
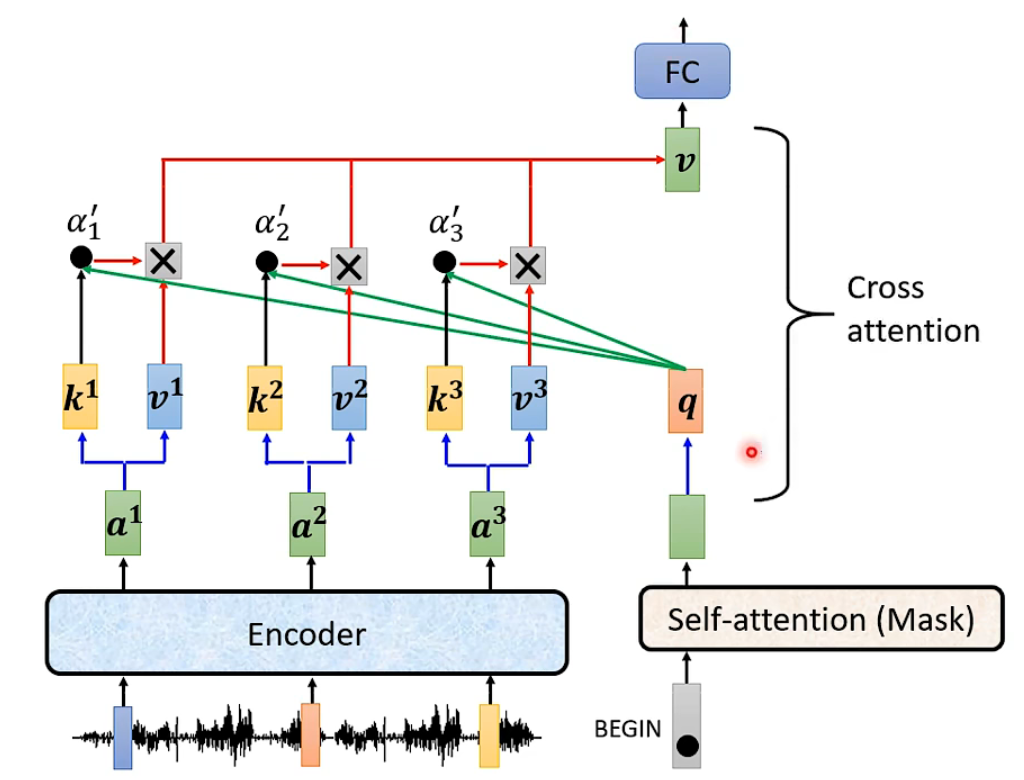
- cross layer 可以用不同类型
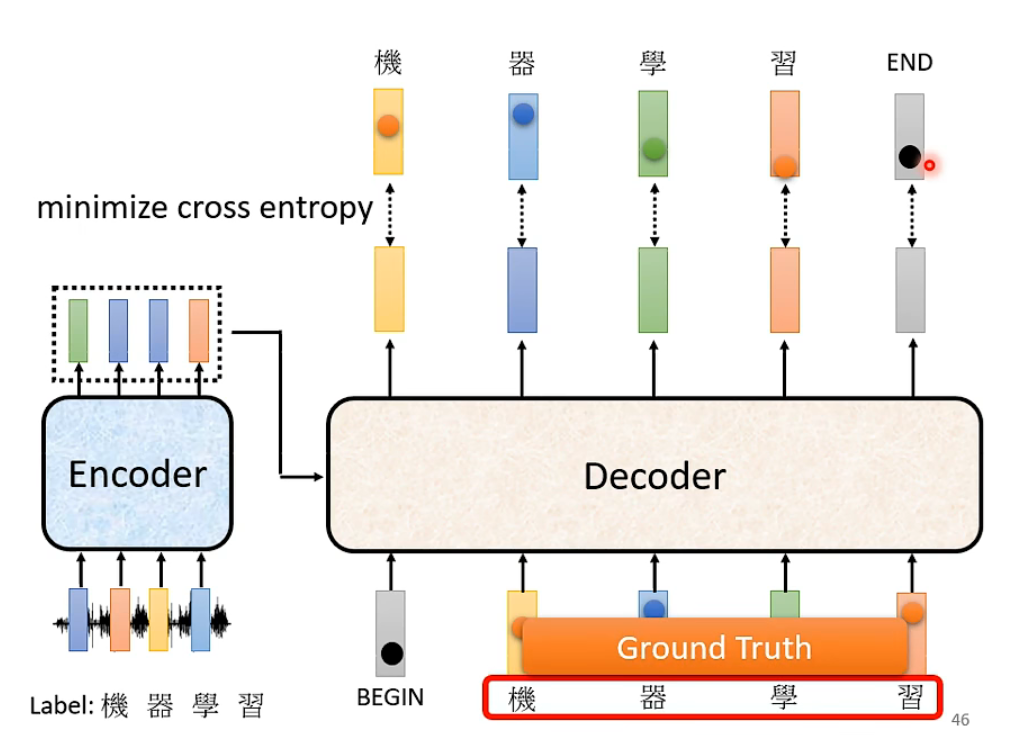
Training
Loss: 每一个词汇的ground truth 和 decoder inference 之后的结果 计算cross entropy
Teacher Forcing
为了更好的训练decoder 防止encoder的error propagation 所以会使用把正确结果放进decoder的输入看能不能输出正确结果
Scheduled Sampling
为了避免没有泛化能力 就给decoder的输入放一些故意的错误(原理有点类似于神经网路 dropout)
[1906.07651] Scheduled Sampling for Transformers (arxiv.org)
Tips
-
copy mechanism
-
guided attention ?
-
Beam Search ?
-
Optimizing evaluation metrics? – BLEU score
- 只能用在testing 的evaluation 不能用在loss是因为不可微 不能反向传递
- when you don’t know how to optimize, just use reinforcement learning!!!
把BLEU score看成reward 把decoder看成agent
[1511.06732] Sequence Level Training with Recurrent Neural Networks (arxiv.org)
图片来源:
Ruiqiang Xiao
MSc student in HKUST
My research interests include distributed robotics, mobile computing and programmable matter.